Was ist Retrieval Augmented Generation (RAG)?

RAG ermöglicht einem KI-System, auf aktuelle und spezifische Daten zuzugreifen, die außerhalb der ursprünglichen Trainingsdaten des Modells liegen. Dadurch können LLMs präzisere und aktuellere Antworten liefern, was besonders in Unternehmenskontexten vorteilhaft ist. Dieser Artikel erläutert, was Retrieval Augmented Generation ist, wie die Architektur funktioniert und welchen geschäftlichen Nutzen dieser Ansatz bietet.
Definition und Grundlagen
Retrieval Augmented Generation bezeichnet ein Softwaresystem, das Information Retrieval mit generativer KI kombiniert. Anstatt ausschließlich sein im Voraus erlerntes Wissen zu nutzen, liefert RAGs LLM die Antworten auf Basis externer Quellen.. Typischerweise greift RAG auf firmeneigene Datenbanken, Dokumente oder sogar das Web zu, um aktuelle Fakten bereitzustellen. So können etwa unternehmensspezifische Details oder brandneue Informationen berücksichtigt werden, die ein herkömmliches LLM allein nicht kennen würde.
Ursprung des Konzepts
Als Konzept wurde Retrieval Augmented Generation im Jahr 2020 durch das AI-Forschungsteam um Patrick Lewis eingeführt. In ihrer Publikation „Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks“ beschrieben sie erstmals detailliert diesen Ansatz.
Seitdem hat RAG in kurzer Zeit große Aufmerksamkeit erlangt: Zahlreiche Wissenschaftler und Industrieexperten haben die Methode aufgegriffen und sehen darin eine Möglichkeit, den Wert generativer KI-Systeme erheblich zu steigern.
Abgrenzung zu klassischen LLM-Ausgaben
Ohne RAG sind LLM-Antworten ausschließlich auf das trainierte Wissen des Modells beschränkt. Das führt zu bekannten Problemen:
- Halluzinierte Antworten, wenn keine echten Fakten vorliegen,
- Veraltete Informationen, die nicht mehr zutreffen,
- Zu allgemeine Aussagen, obwohl aktuelle und präzise Details erwartet werden.
Zudem kann ein Standard-LLM keine Referenzen oder Quellen liefern, was das Vertrauen der Anwender mindert.
RAG setzt hier an: Statt einer Black-Box-Antwort ermöglicht es nachvollziehbare Ausgaben mit integriertem Faktenwissen. Das System holt z.B. bei einer komplexen Frage zunächst relevante Hintergrundinfos aus einer Datenbank und generiert dann eine Antwort, die auf diesem aktuellen Kontext basiert.
Mit KI zum Erfolg – erleben Sie Marketing, das sich selbst optimiert.
Warum ist Retrieval Augmented Generation wichtig?
Sprachmodelle sind leistungsstark, haben aber ohne RAG deutliche Einschränkungen.
Grenzen herkömmlicher Sprachmodelle
Große Sprachmodelle haben beeindruckende Fähigkeiten, stoßen jedoch ohne RAG auf mehrere Beschränkungen:
Wissensgrenze: Ein LLM kann nur auf Informationen zurückgreifen, die in seinen statischen Trainingsdaten enthalten sind.
Halluzinationen: Wenn kein passendes Wissen vorhanden ist, neigen generative Modelle dazu, Antworten zu erfinden. Sie präsentieren erfundene Inhalte mit großer Überzeugung, was für Nutzer schwer erkennbar ist.
Mangelnde Spezifität: Ohne externe Daten antworten LLMs oft vage oder allgemeingültig, selbst wenn der Nutzer etwas Konkretes wissen will.
Keine Quellenangaben: Klassische LLM-Ausgaben bieten keine Einblicke, woher eine Information stammt. Nutzer können die Korrektheit nicht direkt verifizieren, was besonders in kritischen Anwendungen problematisch ist.
Diese Einschränkungen limitieren den Nutzen von LLMs in professionellen Anwendungen. RAG adressiert genau diese Punkte, indem es dem Modell ermöglicht, gezielt aktuelles, autoritatives Wissen abzurufen und einzubinden.
Relevanz für Unternehmen und Forschung
Für Unternehmen bietet RAG einen klaren Mehrwert: Durch die Anbindung des Sprachmodells an firmeneigene Wissensdatenbanken oder Dokumentenarchive können Chatbots und virtuelle Assistenten unternehmensspezifische Fragen zuverlässig beantworten. RAG kann dabei beispielsweise die beste Erklärung zu einem Sachverhalt liefern, sodass Kunden und Mitarbeiter präzise Auskünfte erhalten, die direkt auf den Daten des Unternehmens basieren – sei es zu Produktdetails, internen Prozessen oder neuesten Angeboten. So wird generative KI endlich praktisch nutzbar, anstatt nur allgemeine Informationen zu liefern.
In der Forschung adressiert RAG ein zentrales Problem generativer Modelle: den Zugang zu aktuellem Fachwissen. Statt ein Modell ständig neu zu trainieren, können Forscher mit RAG beispielsweise auf aktuelle Publikationen, Studien oder Daten zugreifen und diese in Echtzeit in Analysen einfließen lassen.
Vorteile von Retrieval Augmented Generation
RAG-Techniken erweitern die Fähigkeiten von LLMs in mehrerer Hinsicht.
Funktionsweise von RAG
Die Funktionsweise eines Retrieval-Augmented-Generation-Systems lässt sich in vier Hauptschritte gliedern.
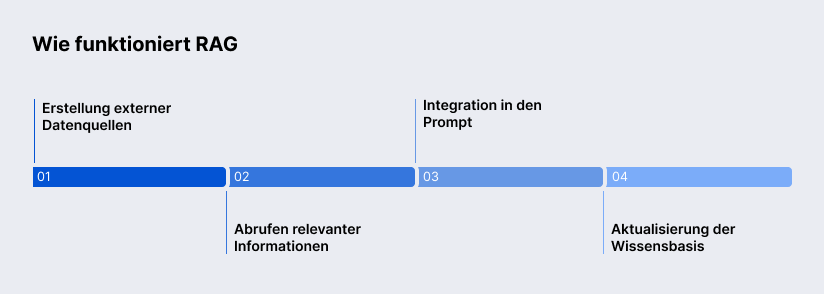
Erstellung der Wissensbasis
Zunächst wird eine externe Wissensbasis aufgebaut, die alle relevanten Informationen enthält. Diese kann aus internen Datenquellen oder externen Quellen bestehen. Große Dokumente werden oft in kleinere Chunks zerlegt, damit gezielter darauf zugegriffen werden kann. Anschließend werden alle Inhalte in numerische Embeddings überführt und in einer Vektordatenbank indexiert. Dabei erhält jeder Daten-Chunk einen Vektor, der seine semantische Bedeutung repräsentiert. Die Vektordatenbank verknüpft diese Vektoren mit den ursprünglichen Inhalten und ermöglicht ein schnelles Durchsuchen des Wissensbestands.
Abrufen relevanter Informationen
Kommt eine Nutzeranfrage (Query) herein, wird sie zunächst ebenfalls als semantischer Vektor dargestellt. Das RAG-System verwendet dann meist eine semantische Suche, um in der Vektordatenbank diejenigen Wissenseinheiten zu finden, die am besten zur Intention der Anfrage passen. Anders als eine rein schlüsselwortbasierte Suche kann die semantische Suche die Bedeutung der Frage erfassen und entsprechende Inhalte auffinden – selbst wenn die Wortwahl unterschiedlich ist. Aus der Wissensbasis werden so die Top-Treffer (oft die relevantesten Textpassagen oder Datensätze) abgerufen. Dieser Retrieval-Schritt ist entscheidend: Die Qualität der späteren Antwort hängt maßgeblich davon ab, wie treffend die gefundenen Informationen sind.
Integration in den Prompt
Die vom Retrieval gelieferten Inhalte werden nun mit der ursprünglichen Benutzerfrage kombiniert und als erweiterter Prompt an das Sprachmodell gegeben. Die LLM RAG-Integration ermöglicht, dass das Modell im Inferenz-Schritt sowohl auf sein angeborenes Weltwissen als auch auf die spezifischen kontextuellen Fakten aus der Wissensbasis zugreifen kann. Das LLM hat bis zu diesem Punkt die Frage selbst noch nicht verarbeitet – es erhält sie jetzt zusammen mit den Kontextinformationen. Das LLM generiert daraufhin die Antwort in natürlicher Sprache. Dank der angereicherten Eingabe kann diese Antwort wesentlich genauer und kontextbezogener ausfallen, als es dem LLM allein möglich wäre.
Aktualisierung der Wissensbasis
Ein großer Vorteil von RAG ist die dynamische Erweiterbarkeit des Wissens. Neue oder geänderte Daten lassen sich fortlaufend in die Vektordatenbank einspeisen – ohne das LLM selbst neu trainieren zu müssen. Dadurch bleibt das System stets auf dem neuesten Stand, z.B. wenn neue Dokumente erscheinen oder sich Fakten ändern. Gelegentlich fließen auch die Interaktionen selbst zurück: Häufige Anfragen und deren Antworten können wiederum indexiert werden, um zukünftige ähnliche Fragen noch effizienter zu beantworten. Insgesamt ist der Betrieb eines RAG-Systems zwar mit kontinuierlichem Aufwand verbunden, doch diese laufende Pflege stellt sicher, dass die KI-Lösung über die Zeit lernt und sich an veränderte Wissensstände anpasst. Im Gegensatz zum starren Wissenshorizont eines einmal trainierten LLM ist ein RAG-System damit deutlich flexibler und langlebiger.
Typische Herausforderungen bei RAG
Trotz seiner Vorteile bringt RAG auch eine Reihe von Herausforderungen mit sich, die es in der Praxis zu beachten gilt.
Unterschiede zu anderen Methoden
Vergleichen wir RAG mit semantischer Suche und Fine-Tuning.
RAG vs. semantische Suche
Semantische Suche und Retrieval Augmented Generation sind verwandte Konzepte, unterscheiden sich aber in der Zielsetzung.
- Semantische Suche findet relevante Dokumente und zeigt Auszüge, die der Nutzer selbst interpretieren muss.
- RAG nutzt diese Ergebnisse und erzeugt daraus automatisch eine verständliche Antwort in natürlicher Sprache.
In der Praxis ergänzen sich beide Methoden also. Will man z.B. nur eine Liste von Dokumenten finden (wie bei einer klassischen Suchmaschine), reicht die semantische Suche aus. Benötigt man hingegen eine konkrete Antwort in Satzform oder eine Zusammenfassung, spielt RAG seine Stärke aus.
RAG vs. Fine-Tuning
Fine-Tuning und RAG sind zwei unterschiedliche Ansätze, um Sprachmodelle für spezifische Aufgaben oder Domänen zu optimieren.
- Beim Fine-Tuning wird das vortrainierte Modell mit zusätzlichen, spezialisierten Daten nachtrainiert, wodurch es firmenspezifisches Wissen und Fachterminologie besser beherrscht. Diese Methode liefert sehr präzise Ergebnisse, ist jedoch zeit- und rechenintensiv und erfordert bei neuen Informationen ein erneutes Training.
- Bei der RAG bleibt das Modell unverändert, während eine Retrieval-Schicht externe, relevante Informationen bei Anfragen einspeist. Der Architekturansatz von RAG erlaubt dabei, externe Wissensquellen dynamisch einzubinden, ohne das Modell selbst jedes Mal anzupassen.
In der Praxis werden beide Methoden oft kombiniert: Das Modell wird grob feingetunt und erhält zusätzlich über RAG tagesaktuelle Daten, wodurch Präzision und Aktualität optimal miteinander verbunden werden.
Anwendungsfälle für RAG
RAG eröffnet Unternehmen die Möglichkeit, große Wissensbestände effektiv zu nutzen und auf Anfragen schnell und präzise zu reagieren.

Unternehmensinterne Wissensdatenbanken
Viele Unternehmen verfügen über enorme Mengen an dokumentierten Wissen – von Handbüchern und Richtlinien über Projektberichte bis zu Intranet-Seiten. Retrieval Augmented Generation eignet sich, um solche interne Wissensdatenbanken nutzbar zu machen. Mitarbeiter können in natürlicher Sprache Fragen stellen und das RAG-System durchsucht die internen Dokumente nach der passenden Antwort.
Der Chatbot bzw. virtuelle Assistent liefert dann eine konsolidierte Antwort, oft inklusive Verweis auf das Dokument, aus dem die Information stammt. Dies erhöht die Geschwindigkeit, mit der Mitarbeiter oder auch neue Teammitglieder an verlässliche Informationen gelangen.
Kundenservice und Chatbots
RAG ermöglicht leistungsfähige Chatbots, die auf Produkt-FAQs, Handbücher oder Support-Tickets zugreifen und Kunden in Echtzeit präzise Antworten liefern. Selbst ungewöhnliche Fragen können korrekt beantwortet werden, wodurch ein 24/7-Service möglich wird. So steigt die Kundenzufriedenheit, da schnelle, belastbare Antworten mit Verweisen auf relevante Quellen kombiniert werden, was besonders für Banken, Telekommunikation und E-Commerce von Vorteil ist.
Medizinische Forschung und Life Sciences
Im medizinischen Bereich und in den Life Sciences fallen enorme Daten- und Textmengen an – von wissenschaftlichen Veröffentlichungen über klinische Studien bis hin zu Patientenakten. RAG bietet hier die Chance, komplexe Recherchen zu automatisieren und Experten zeitlich zu entlasten.
E-Commerce und Produktempfehlungen
Auch im E-Commerce ergeben sich durch Retrieval Augmented Generation spannende Möglichkeiten. Online-Shops können RAG nutzen, um produktbezogene Fragen der Kunden zu beantworten oder personalisierte Empfehlungen auszusprechen. Ein Kunde fragt einen Mode-Chatbot, und das System könnte auf Basis der Produktdatenbank, Lagerbestände und vielleicht auch Kundenbewertungen eine Antwort generieren, die passende Jacken vorschlägt – inklusive Hinweis, dass diese gerade verfügbar sind. Ohne RAG müsste der Chatbot auf vordefinierte Zuordnungen zurückgreifen oder die Frage unbeantwortet lassen.
Ein weiterer Anwendungsfall sind Produktempfehlungen: RAG-Systeme können Kundendaten mit aktuellen Produktinformationen kombinieren, um personalisierte Empfehlungen zu generieren.
Schritt-für-Schritt-Anleitung zur Implementierung von RAG
Für Unternehmen, die RAG in die Praxis umsetzen möchten, sind folgende Schritte hilfreich.
Best Practices und Empfehlungen
Bei der Implementierung von Retrieval Augmented Generation sollten einige Best Practices berücksichtigt werden, um Sicherheit, Leistung und Zuverlässigkeit zu gewährleisten.
Sicherheit und Datenschutz
Da RAG-Modelle auf umfangreiche Datenquellen zugreifen, ist es wichtig, Zugriffsbeschränkungen einzubauen. Nicht jeder Nutzer soll alle Dokumente sehen dürfen. Setzen Sie z.B. Sicherheitsmechanismen auf Dokumentebene ein, um vertrauliche Informationen zu schützen. Rollen- und Rechtemanagement lässt sich auch im Retrieval implementieren, indem die Suche je nach Benutzer nur bestimmte Index-Bereiche durchsucht. Darüber hinaus sollten sensible Daten möglichst anonymisiert oder maskiert in die Wissensbasis aufgenommen werden, um den Schutz persönlicher Informationen zu gewährleisten. Falls ein externer Cloud-Dienst für die Vektordatenbank genutzt wird, achten Sie auf Verschlüsselung der gespeicherten Vektoren und Übertragungswege.
Skalierbarkeit und Performance
Die Skalierung eines RAG-Systems ist entscheidend, da Embedding-Berechnung, Vektorsuche und LLM-Inferenz rechenintensiv sind und bei vielen Anfragen zum Performance-Flaschenhals werden können. Optimierungen umfassen Lastverteilung, GPU-Auslagerung der Embeddings, Sharding oder Partitionierung der Vektor-Indices, Caching häufiger Fragen sowie den Einsatz skalierbarer Hardware oder Cloud-Services. So bleibt das System auch bei großen Datenmengen und hohem Anfrageaufkommen schnell und reaktionsfähig.
Monitoring und Optimierung
Der Betrieb eines RAG-Systems erfordert kontinuierliches Monitoring von Qualität und Performance. Wichtige Metriken sind Retrieval-Präzision und Antwortgenauigkeit, ergänzt durch die Protokollierung von Fehlfällen wie Halluzinationen oder unbeantworteten Fragen. Auf Basis dieser Daten lässt sich die Pipeline optimieren: zusätzliche Quellen einbinden, irrelevante Dokumente entfernen oder Prompting anpassen. Ebenso wichtig ist die regelmäßige Pflege der Wissensbasis, um veraltete Informationen zu aktualisieren. Erfolgreiche RAG-Projekte werden daher als laufende Zusammenarbeit zwischen Fachexperten und AI-Ingenieuren betrieben, um langfristige Zuverlässigkeit und Relevanz sicherzustellen.
Zukunftsperspektiven von RAG
RAG entwickelt sich weiter und eröffnet neue Möglichkeiten über die klassische Textverarbeitung hinaus.
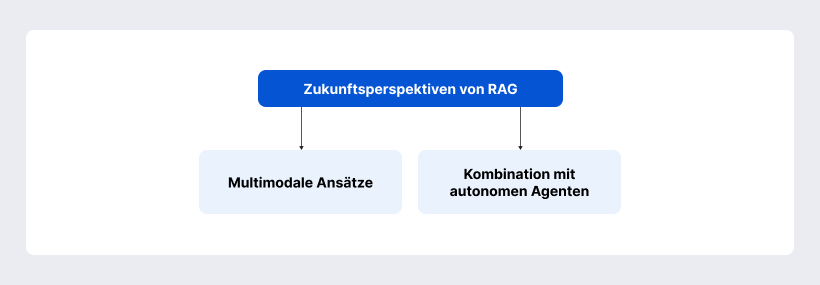
Multimodale Ansätze
Zukünftige RAG-Systeme könnten nicht nur Text, sondern auch Bilder, Videos, Audio oder Tabellen einbeziehen. So ließen sich z.B. Handbuchtexte mit passenden Schaubildern kombinieren oder medizinische Studien mit Röntgenbildern verknüpfen. Technisch erfordert das neue Einbettungsmodelle und Suchstrategien, doch Unternehmen wie Nvidia und Microsoft arbeiten bereits an solchen Plattformen.
Kombination mit autonomen Agenten
RAG kann künftig auch komplexe KI-Agenten unterstützen, die Aufgaben selbstständig planen und ausführen. Ein Business-Agent könnte per RAG aktuelle Daten sammeln, analysieren und Handlungsempfehlungen ableiten. Erste Systeme wie AutoGPT zeigen, wie Agenten Informationen aktiv einbinden. Die Verbindung von RAG und autonomen Agenten eröffnet neue Anwendungen, von Robotic Process Automation bis zu proaktiven digitalen Assistenten.
Welche RAG-Dienstleistungen bietet SaM Solutions an
Als Softwareentwicklungs- und IT-Beratungsunternehmen unterstützt SaM Solutions Kunden bei der Integration von Retrieval Augmented Generation und KI-Agenten in ihre Anwendungen.
Wir begleiten Sie von der Analyse Ihrer Anforderungen über die Auswahl der passenden Architektur und Vektordatenbank bis zur Entwicklung maßgeschneiderter Pipelines für semantische Suche und Retrieval.
Langfristig bieten wir Wartung und Support, um Indizes zu aktualisieren, die Relevanz der Ergebnisse zu verbessern und neue Datenquellen einzubinden – so bleibt Ihre KI stets präzise und aktuell.

Zusammenfassung
Retrieval Augmented Generation kombiniert Information Retrieval mit generativer KI, sodass Modelle aktuelle, externe Wissensquellen einbeziehen können. Dadurch lassen sich präzisere, kontextbezogene Antworten generieren, die klassische LLMs ohne RAG nicht liefern können.
RAG verbessert die Genauigkeit, liefert aktuelle Informationen, spart Kosten im Vergleich zu Fine-Tuning und erhöht Transparenz durch Quellenangaben. Unternehmen profitieren in Wissensmanagement, Kundenservice, E-Commerce und Life Sciences.
Zuerst wird eine Wissensbasis aufgebaut und mit Embeddings indexiert. Dann sucht das System passende Informationen und fügt sie in die Frage an das LLM ein. Die Wissensbasis kann jederzeit aktualisiert werden, ohne das Modell neu zu trainieren.
Bei RAG ist es wichtig, auf Datenqualität, Datenschutz und passende Zugriffsbeschränkungen zu achten. Das System sollte skalierbar sein – etwa durch Lastverteilung, GPU-Auslagerung, Sharding der Vektoren und Caching häufiger Anfragen. Außerdem empfiehlt sich ein kontinuierliches Monitoring von Leistung und Antwortqualität, um das System laufend zu verbessern.
RAG entwickelt sich zu multimodalen Systemen (Text, Bild, Audio, Video) und kann in Kombination mit autonomen KI-Agenten komplexe Aufgaben automatisieren, wodurch neue Anwendungsfelder entstehen.
FAQ